After almost 5-6 years of dominance in big data world, Hadoop is finally come under fire from the upcoming new architectures. Recently Hadoop is facing lots of competition from lots of so called “Hadoop Killers”. Yes, I am a Hadoop lover but there have been some areas from starting where it is lagging behind like real time calculations, processing on small data set, CPU intensive problems, continuous computation, incremental updates etc.
Recently, LexisNexis open sourced its Hadoop killer claiming to outperform it in both data volumes and response time. It looks to me as a definite killer so I decided to have a look into it and compare it with Hadoop. Before taking a closer look into head to head comparison here is a brief introduction to HPCC for too lazy developers to visit HPCC site.
HPCC (High Performance Computing Cluster) is a massive parallel-processing computing platform that solves Big Data problems. The platform is now Open Source! |
HPCC systems directly take on Hadoop, which is not wrong as far as functionality is concerned. But architecturally they are not comparable. Hadoop is based on Map reduce paradigm where as HPCC is not map reduce its something else. This is what I am able to figure out from their public documents.
Take a look of architectural diagram of HPCC; I am not going into detail of everything here.

However there are few places where HPCC have an edge over Hadoop:
- Developers IDE
- Roxie component
Places where both are on same track:
- Thor ETL component: Compares directly to map reduce
- ECL: High level programming language just like Pig
Now let’s talk in actual numbers, I have performance tested both frameworks on few standard use cases like N-grams finder and Word count example. Interestingly found mixed bench-marking numbers for both tests. HPCC performed well for N-gram finder whereas Hadoop did better in Word count use case. Here are the exact numbers of our tests:
Round 1: N-Gram Finder

Score: HPCC: 1, Hadoop: 0
Round 2: Word Counter

Score: HPCC: 1, Hadoop: 1
Yeah, with this mixed nature of test result we cannot conclude anything. So, let’s compare them on some critical and curial non-functional parameters.
Round 3: Licensing
The biggest issue HPCC is going to face is its licensing model. Open source world has never honored AGPL very well. If HPCC wants to compete and grow big like Hadoop has done is last four five years then they must have rethink about licensing model.
Whereas, on the contrary Hadoop with its Apache 2.0 licensing model results in many enterprises as well as individual to contribute to this project and help it to grow bigger and better.
Score: HPCC: 1, Hadoop: 2
Round 4: Adoption Rate
This is not a very big factor as compared to others but taken the last point HPCC is bound to face adaptation issues for developers and companies of all shapes and sizes.
For developers hurdle would to adapt ECL programming language and developers never feel comfortable to deal with a new language. On the other hand Hadoop’s development environment is higly flexible to any kind of developers. MR jobs can be written Java, C++, and Python etc. and for scripting background Pig is the easiest way to go. Thanks to hive which allows DBA to use its SQL-ish syntax.
Score: HPCC: 1, Hadoop: 3
Round 5: Ecosystem and related tools
Even if we consider HPCC to be more efficient than Hadoop but I feel HPCC guys are a bit late to enter into Open source world. Hadoop has put on lots of weight!, in last 5 years it has travelled a long way from a Map Reduce - parallel distributed programming framework to a de facto for big data processing or data warehouse solution. Contrary, am afraid HPCC is still more or less a big data framework only.
So, HPCC is not competing with another framework but an ecosystem which has been developed in recent years around Hadoop. It’s actually competing with Hadoop and its army, that’s where real strength exists.
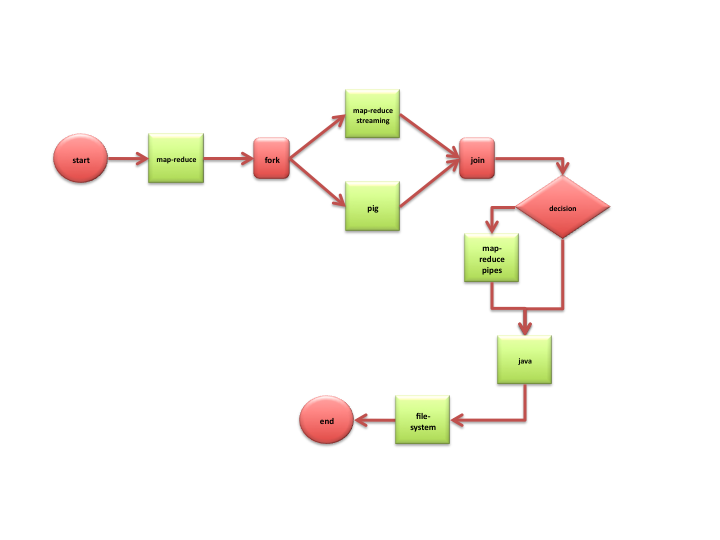
Take a look how Hadoop has evolved in recent years for clearer picture.

Score: HPCC: 1, Hadoop: 4
Final Score: Clear Hadoop Dominance
Let’s talk practical, Hadoop is not the most efficient big data architecture. In fact, it is said that it’s anything from 10x-10000x too slow for what's required. There are tools and technologies in place which performs way better than Hadoop in their own domain. Like for database joins any SQL is better, for OLTP environment we have VoltDB, for real time analytics Cloudscale performs much better, for supercomputing/modeling/simulations MPI and BSP are the clear winners, Pregel is there for graph computing, Dremel for interactive big data analytics, Caffine or Percolator can’t be compared with Hadoop of incremental computing of big data.
Strength of Hadoop exists in its huge ecosystem and that’s where its USP is. It offers Hive for SQL-ish requirements, HBase for key value store, Mahout for learning machines, Oozie for workflow management, Flume for log processing , Blur for search, Sqoop for interaction with rdbms etc etc. and lastly vast developers network. So, when we talk about totality when creating a data warehouse or BI tool Hadoop would remain the obvious choice presently.